|
|
|
|
|
|
In recent years, vision and language models (VLMs) have demonstrated impressive results on a wide variety of tasks.
However, recent empirical studies have shown that even the strongest VLMs struggle to perform compositional scene understanding, including identifying object attributes and inter-object relations.
Understanding the structure of visual scenes is a fundamental problem in machine perception and has been explored extensively. In particular, datasets with scene graph (SG) annotations, such as the Visual Genome (VG), have been collected and used to improve scene understanding models.
However, such datasets are expensive to collect at scale and relatively small compared to those used in training VLMs.
This raises the following questions:
(1) Can small datasets containing SG annotations be utilized to finetune VLMs and improve compositional scene understanding?
(2) How should the model and training be adapted to best use this data?
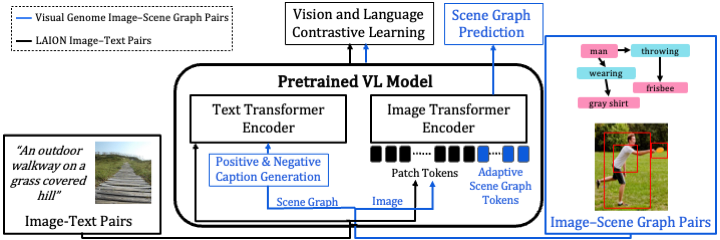
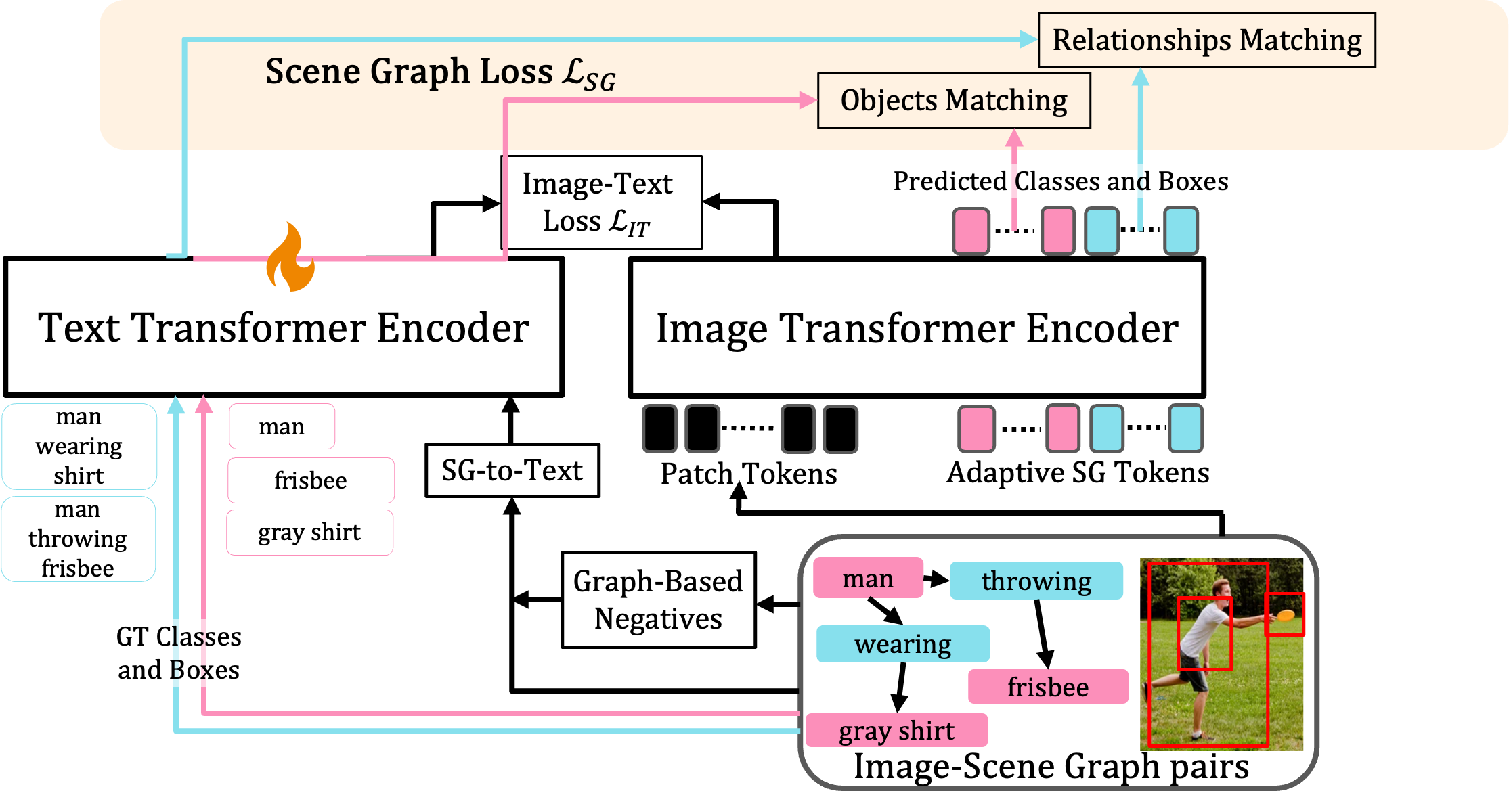
Here we show that it is indeed possible to improve VLMs using image-SG pairs by integrating components that incorporate structure into both visual and textual representations.
Our first step is to convert SGs into highly detailed captions. A naive approach would be to finetune VLMs on these image-text pairs, however, this approach does not sufficiently improve performance. This is also aligned with recent work showing that contrastive learning approaches allow the model to concentrate mainly on object labels disregarding other important aspects. Hence, We use the SG to generate hard-negative captions that highlight structural aspects when used with an appropriate loss.
Next, we turn to introduce structure into the visual representation. Inspired by prompt learning approaches, we incorporate into the image transformer encoder a set of ``Adaptive Scene Graph Tokens'', which interact with the patch and CLS tokens via attention. By training these tokens to predict SG information, the encoder can capture better structured representations.
 |
Roei Herzig*, Alon Mendelson*, Leonid Karlinsky, Assaf Arbelle, Rogerio Feris, Trevor Darrell, Amir Globerson Incorporating Structured Representations into Pretrained Vision & Language Models Using Scene Graphs Hosted on arXiv |